I’ve got an error in Open Search using the search#DataDocuments’s orderByFields field. It says:
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Text fields are not optimised for operations that require
per-document field data like aggregations and sorting, so these operations
are disabled by default. Please use a keyword field instead. Alternatively,
set fielddata=true on [categoryName] in order to load field data by
uninverting the inverted index. Note that this can use significant memory."
}
],
"status": 400
}
I’m wondering if anyone has encountered this before, and if they have any ideas on how to fix it. I believe that this error has something to do with aggregations needing a specific format to untokenize the fields to their raw text values.
One interesting thing about this is that sorting works with what I can tell primary key fields, but not others. Is there a way to change this functionality? I’m not seeing anything in the Data Search Documentation or the data model.
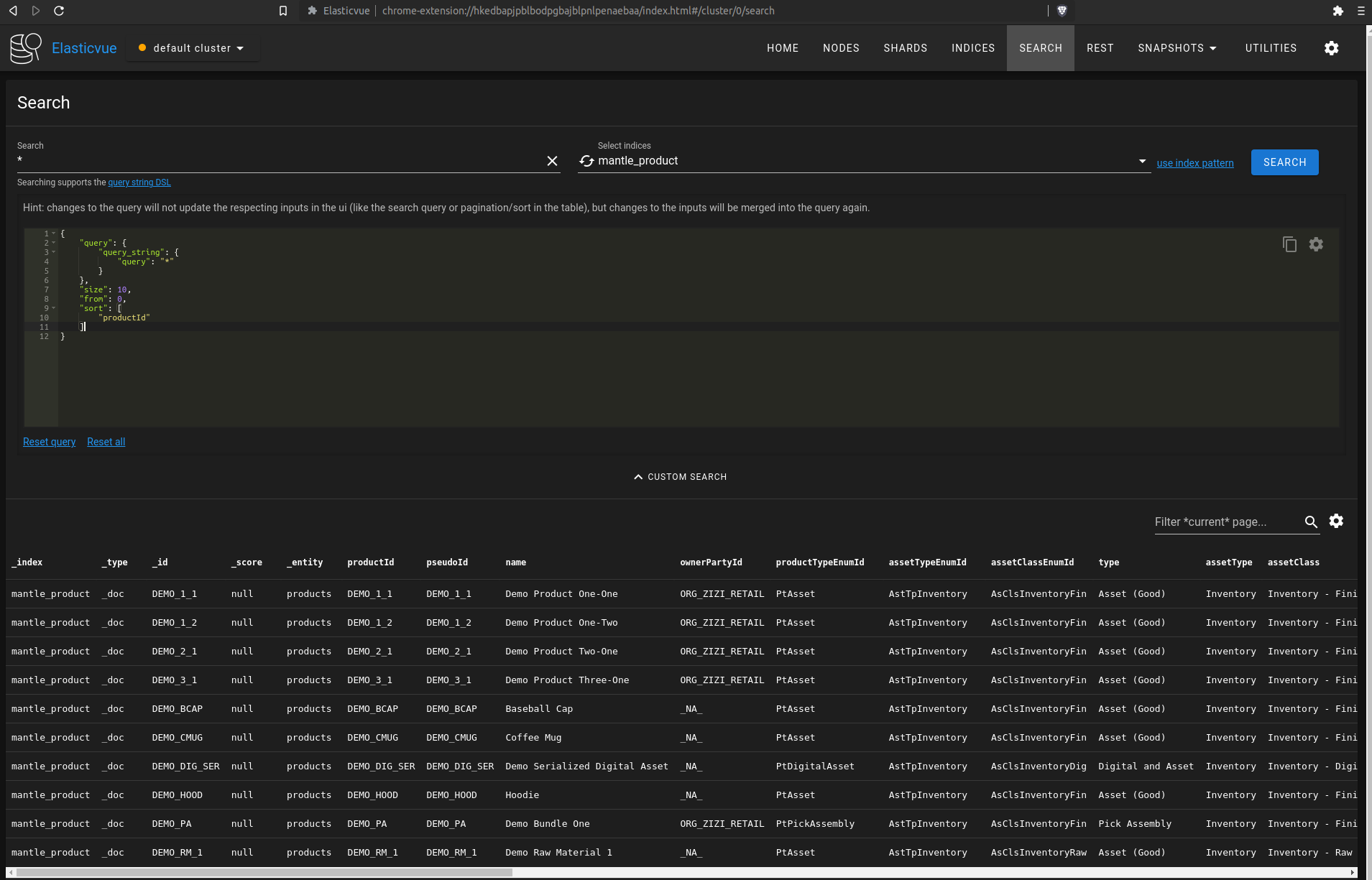
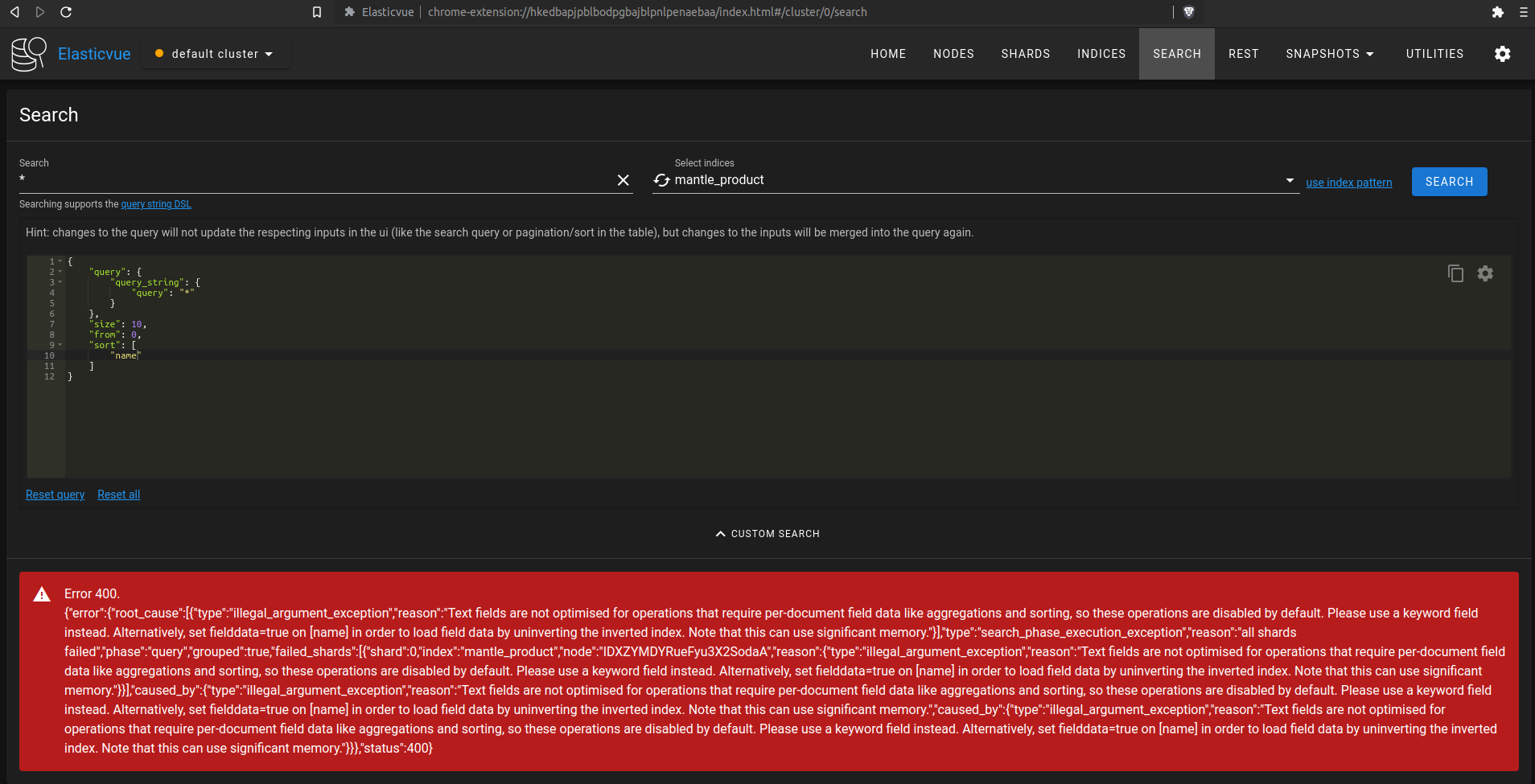
I was able to replicate this problem in Elastic Search also. To replicate, go to an elastic or open search instance with a tool like Elastic View. Navigate to the mantle_product index and add a string productId to the sort query parameter in Custom Search:
The data types for text in ElasticSearch are funny, optimized for search (tokenized) or for lookup and sort. For more info see the sortable field on the DataDocumentField entity:
This is used by the code that sends JSON document schema info in what ElasticSearch calls a ‘mapping’. This code is in the method ElasticFacadeImpl.makeElasticSearchMapping()
What this does is add a sub-field called ‘keyword’ of type keyword and then in search code sort by the categoryName.keyword field instead of the non-sortable categoryName field (tokenized for search).
For one example of code that handles this see the orderByFields field in the search#Party service: