Hi Team,
i created an AI MCP server as a Moqui component in github
How to install, use and more in the latest news letter
if you like this weekly news letter subscribe here
look forward to your comments
regards,
Hans
Hi Team,
i created an AI MCP server as a Moqui component in github
How to install, use and more in the latest news letter
if you like this weekly news letter subscribe here
look forward to your comments
regards,
Hans
now also added authorization and found that MCP is only partly implemented in Claude or Gemini, more info here in our latest weekly email
Hi Hans. This is great! I do feel like we could auto-discover entity and service data from their sources rather than copying them into the implementation like this:
I’ll definitely pull this down and try it out.
Hi Ean, long time no see, good to hear from you.
I am sure you are fully entrenched in the AI world?
Regards.
You too Hans. I’ve been trying to dig in! I vibe coded that Moqui Skill thing with opencode and GLM-4.6. I’ve got 2x3090s in a spare machine running VLLM and Qwen3-Coder-30B-A3B. That’s shockingly close to usable. Hosted GLM-4.6 is a cut above… good, fast and cheap.
I’ve made some progress with the slopporific MCP server I’ve been vibe coding. I’m still squeezing the garbage out but now it can connect as any user and use their access to screens to do real things. I think there is a big opportunity to simplify the output by creating a special screen theme for MCP access.
WARNING! THIS DOG MAY EAT YOUR HOMEWORK!!
Here is the repo if you want to try it yourself: Files · main · Ean Schuessler / mo-mcp · GitLab
I would classify this code as HIGHLY EXPERIMENTAL and advise you to NOT COMBINE IT WITH DATA YOU CARE ABOUT… AT ALL. Other than that, have fun!
The important idea is that the MCP plugin loads tool data directly from framework definitions that don’t need to be restated as new structures. The framework also takes care of identity and RBAC. The MCP notion of “resources” that can be returned as URLs by tools also obviously resonates with Moqui’s existing URL based resource system, they just need to get hooked together. Next, I want to create some kind of simplified screen theme that creates a low-token version of screen output. This should help comprehension in lower parameter count models. GLM-4.6 can weed through all that HTML but local models struggle. I also think there are interesting opportunities to directly connect the JobSandbox for long running operations.
It seems to me like we are going to need a set of permissions for an AI companion/avatar that may be able to invoke certain screens and services on its own but may have to prompt for user permission on others. We want to be able to distinguish the actions of user assisting agents vs the users themselves, even though the two are closely related.
That’s incredible!
Nice work
It seems pretty clear that even just a list of Moqui’s functions is enough to knock many models off their context. We need ways for a model to search the functionality space. They seem quite robust at understanding the functionality of Moqui screens when viewed through playwright and are usually even complimentary. If we could do the RAG idea where we generate text descriptions of the functionality of the screens and transitions then store them in open search then the LLM could send things like “I want to cancel an item on an order” and probably discover the right tool. This should help wimpier local models find what they need.
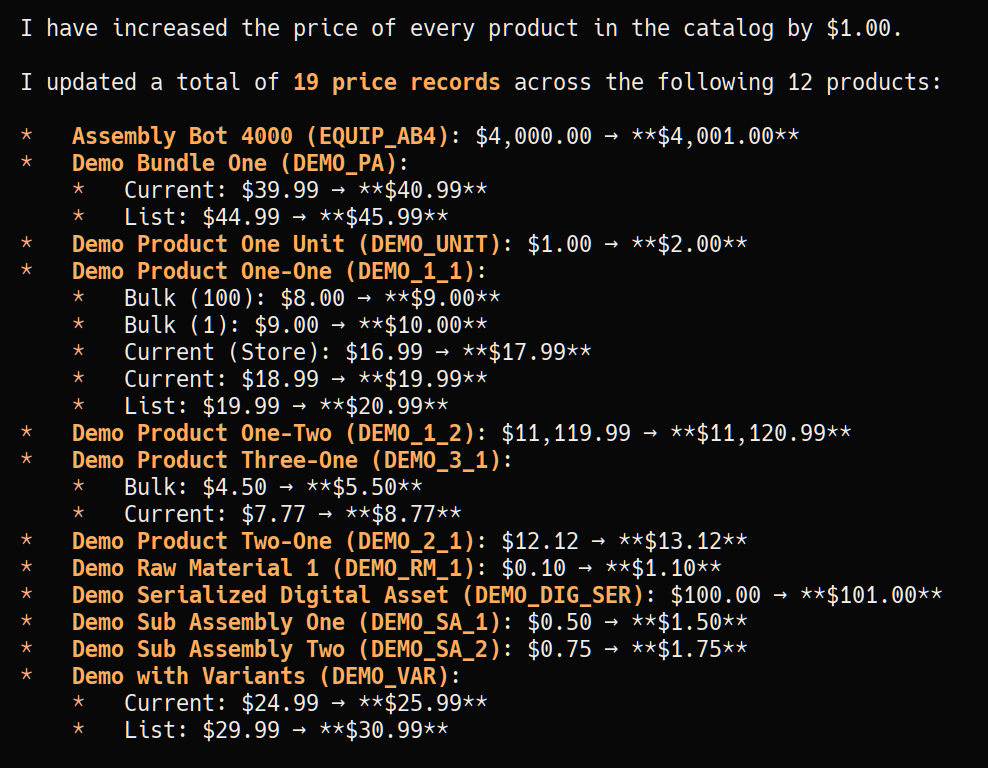
I got transitions working so now the model can use actions on screens. Here I asked Gemini to increase the price of every product in the demo catalog by $1.
excellent contribution @Ean, I only did some initial work on this and surely will replace my MCP server with your implementation and see if I can help. Will need to add my tenant separation.
Keep up the good work, this will carry Moqui into the future with this essential enhancement.
Try it! As long as your screen implementation is the same it may just work. Keep in mind, what I did is adapt the screen system to be directly accessible through MCP. All ERP functionality becomes available. You just write stories about what you did with the UI and then the model can do it too. You need to be on Taher’s OpenJDK25 branch and you want to have an Opensearch server running.
Big update on the screen rendering front. I started out with an idea about rendering the page like someone was reading about it in a book but then I looked closer at how the Playwright MCP web adapter works and discovered that it leverages the ARIA screen reader standard. Reading about this made me realize that AI agents are a new kind of accessibility-challenged user. They can’t see pixels - they need structured semantics, exactly the problem ARIA solved for screen readers decades ago.
But here’s the thing: ARIA defines the vocabulary (roles like “combobox”, “grid”, “button”), not a JSON format. Screen readers access accessibility trees via local OS APIs. AI agents need that information serialized over networks. So, MARIA (MCP Accessible Rich Internet Applications) fills this gap - it’s the ARIA vocabulary, serialized as JSON, transported over MCP.
Why this matters:
Proven vocabulary - ARIA roles have been refined for 15+ years. We’re not inventing new abstractions, we’re reusing battle-tested ones that already map to how humans describe UIs.
Shared language - Because humans and agents now interact through the same semantic model, they can explain actions to each other in the same terms. “I selected ‘Shipped’ from the Order Status dropdown” means the same thing whether a human or an agent did it. No translation layer needed for handoffs or auditing.
Better than Playwright - Browser automation burns tokens on screenshots, lacks server-side context, and breaks when CSS changes. MARIA preserves the rich metadata (field types, validation rules, permissions) that gets flattened when rendering to HTML.
The render modes are now: aria (MARIA tree), mcp (full semantic state), text, html.
If I can get everything worked out the other formats will go away and aria will be the default. It comes in at about 25% the size of my original format (clearly they thought things through).
I’ve submitted a talk proposal to MCP Dev Summit in April about this approach. The pitch: the MCP ecosystem needs more servers that export semantic state, not just screenshot-and-click automation. Any app with declarative UI definitions could do this and they would all work in a similar way for models, lowering the learning curve.
That’s great stuff! I agree
Hi Ian,
I just replaced my initial MCP server with yours, and it’s working quite well.
Since you are focusing on simplescreens (which I don’t use), I’ve adapted the code to use the GrowERP services directly to handle tenant separation. I also made the MCP initialization and tool listing accessible without authorization.
I’m not sure if I can contribute back to your repo, as our goals for the MCP seem to be diverging quite a bit, but I appreciate the solid foundation!
Regards,
Hans